🌲长青 #OS #Rust
这里是 rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档的阅读笔记。解释一下文章标题: Bare Metai (裸机平台),在裸机平台上的软件没有传统操作系统支持。我们的目标是在这样一个裸机平台上编写一个应用程序,功能是打印出 HelloWorld!
应用程序执行环境与平台支持
编程工作能够如此方便简洁并不是理所当然的,实际上有着多层硬件和软件工具和支撑环境隐藏在它背后,才让我们不必付出那么多努力就能够创造出功能强大的应用程序。生成应用程序二进制执行代码所依赖的是以 编译器 为主的 开发环境 ;运行应用程序执行码所依赖的是以 操作系统 为主的 执行环境 。
本章主要是讲解如何设计和实现建立在裸机上的执行环境,并让应用程序能够在这样的执行环境中运行。从而让同学能够对应用程序和它所依赖的执行环境有一个全面和深入的理解。
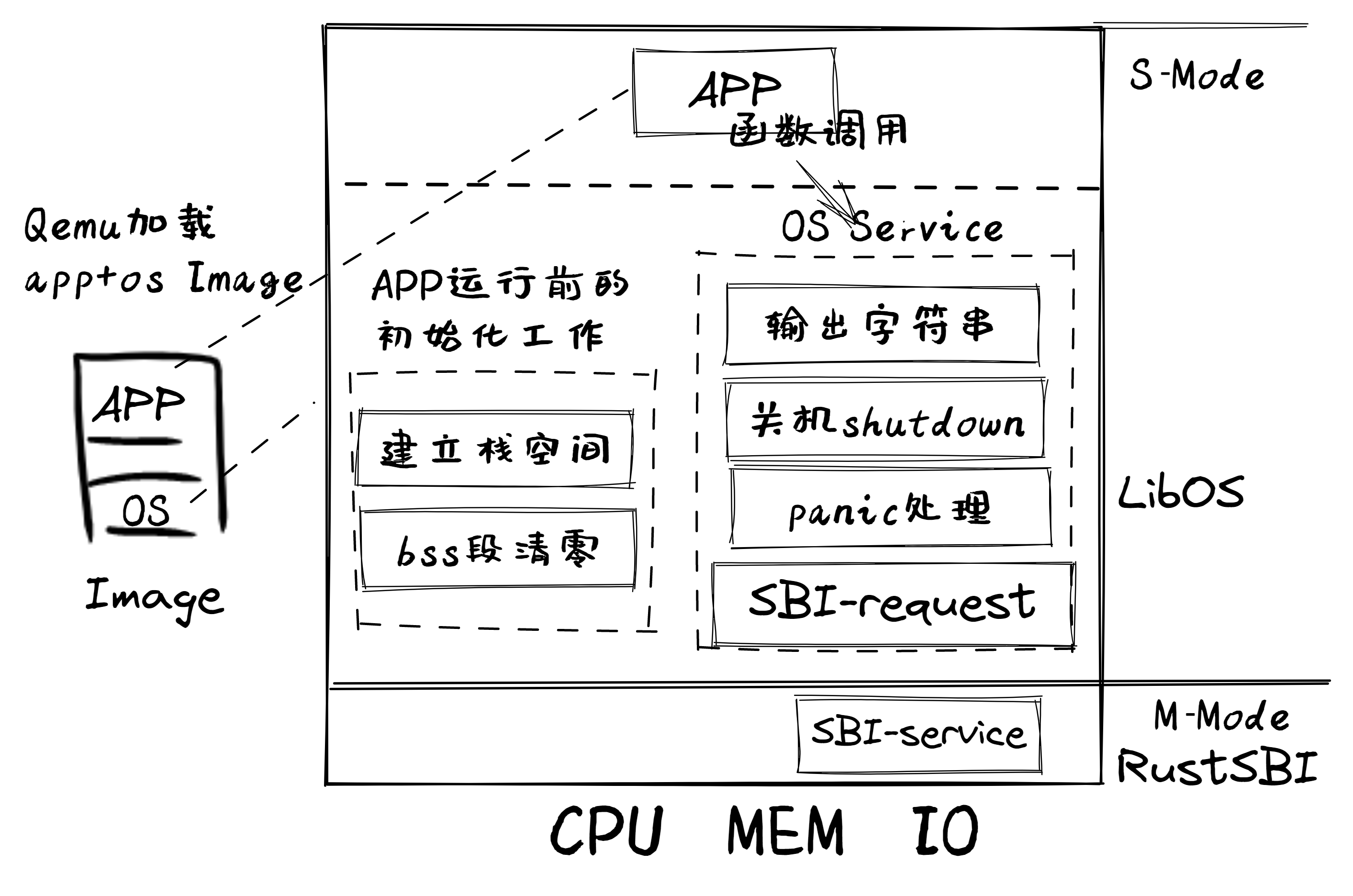
本章设计实现了一个支持显示字符串应用的简单操作系统–“三叶虫”操作系统 – LibOS,它的形态就是一个函数库,给应用程序提供了显示字符串的函数。
库操作系统(Library OS,LibOS)
LibOS 以函数库的形式存在,为应用程序提供操作系统的基本功能。它最早来源于 MIT PDOS 研究小组在1996年左右的 Exokernel(外核)操作系统结构研究。Frans Kaashoek 教授的博士生 Dawson Engler 提出了一种与以往操作系统架构大相径庭的 Exokernel(外核)架构设计 1 ,即把传统的单体内核分为两部分,一部分以库操作系统的形式(即 LibOS)与应用程序紧耦合以实现传统的操作系统抽象,并进行面向应用的裁剪与优化;另外一部分(即外核)仅专注在最基本的安全复用物理硬件的机制上,来给 LibOS 提供基本的硬件访问服务。这样的设计思路可以针对应用程序的特征定制 LibOS ,达到高性能的目标。
这种操作系统架构的设计思路比较超前,对原型系统的测试显示了很好的性能提升。但最终没有被工业界采用,其中一个重要的原因是针对特定应用定制一个LibOS的工作量大,难以重复使用。人力成本因素导致了它不太被工业界认可。
应用程序执行环境
计算机科学中遇到的所有问题都可通过增加一层抽象来解决。
All problems in computer science can be solved by another level of indirection。
– 计算机科学家 David Wheeler
现代编译器工具集(以 C 或 Rust 编译器为例)的主要工作流程如下:
- 源代码(source code) –> 预处理器(preprocessor) –> 宏展开的源代码
- 宏展开的源代码 –> 编译器(compiler) –> 汇编程序
- 汇编程序 –> 汇编器(assembler)–> 目标代码(object code)
- 目标代码 –> 链接器(linker) –> 可执行文件(executables)
目标平台与目标三元组
为什么需要知道目标平台?
编译器在将源代码通过编译、链接得到可执行文件的时候需要知道程序要在哪个 平台 (Platform) 上运行才能最后生成可执行文件。这里平台主要是指 CPU 类型、操作系统类型和标准运行时库的组合。
- 如果用户态基于的内核不同,会导致系统调用接口不同或者语义不一致;
如果底层硬件不同,对于硬件资源的访问方式会有差异。特别是如果 ISA 不同,则向软件提供的指令集和寄存器都不同。
编程语言怎么处理目标平台!
Rust编译器通过 目标三元组 (Target Triplet) 来描述一个软件运行的目标平台。
我们选择 riscv64gc-unknown-none-elf 目标平台。
- 这其中的 CPU 架构是 riscv64gc
- CPU 厂商是 unknown
- 操作系统是 none
- elf 表示没有标准的运行时库(表明没有任何系统调用的封装支持),但可以生成 ELF 格式的执行程序。
Rust 标准库与核心库
编程语言的标准库比如Rust 语言标准库–std 或三方库的某些功能会直接或间接的用到操作系统提供的系统调用。但目前我们所选的目标平台不存在任何操作系统支持。
幸运的是,Rust 有一个对 Rust 语言标准库–std 裁剪过后的 Rust 语言核心库 core。core库是不需要任何操作系统支持的
移除标准库依赖
不是说修改编译器编译选项就可以完成针对不同执行环境的编译的,我们需要修改我们的代码改造哪些需要用到之前依赖的执行环境,当然在你没有改造完成之前你也不会编译成功的😂。
提供 panic_handler 功能应对致命错误
在使用 Rust 编写应用程序的时候,我们常常在遇到了一些无法恢复的致命错误(panic),导致程序无法继续向下运行。这时手动或自动调用 panic! 宏来打印出错的位置,让软件能够意识到它的存在,并进行一些后续处理。 panic! 宏最典型的应用场景包括断言宏 assert! 失败或者对 Option::None/Result::Err 进行 unwrap 操作。所以Rust编译器在编译程序时,从安全性考虑,需要有 panic! 宏的具体实现。
更底层的核心库 core 中只有一个 panic! 宏的空壳,并没有提供 panic! 宏的精简实现。因此我们需要自己先实现一个简陋的 panic 处理函数,这样才能让“三叶虫”操作系统 – LibOS的编译通过。
移除 main 函数
语言标准库和三方库作为应用程序的执行环境,需要负责在执行应用程序之前进行一些初始化工作,然后才跳转到应用程序的入口点(也就是跳转到我们编写的 main 函数)开始执行。事实上 start 语义项代表了标准库 std 在执行应用程序之前需要进行的一些初始化工作。由于我们禁用了标准库,编译器也就找不到这项功能的实现了。
最简单的解决方案就是压根不让编译器使用这项功能。我们在 main.rs 的开头加入设置 #![no_main] 告诉编译器我们没有一般意义上的 main 函数,并将原来的 main 函数删除。在失去了 main 函数的情况下,编译器也就不需要完成所谓的初始化工作了。
介绍执行环境 Qemu——内核执行的基础
接下来两节我们将进行构建“三叶虫”操作系统的第二步,即将我们的内核正确加载到 Qemu 模拟器上,使得 Qemu 模拟器可以成功执行内核的第一条指令!
想要加载内核的话,我们首先需要了解执行平台的相关资料,把我们的内核放到哪里才能被正确执行?怎么把 qemu 的控制权转移到我们的内核。
Qemu 的工作模式
在 Qemu 模拟的 virt 硬件平台上,物理内存的起始物理地址为 0x80000000 ,物理内存的默认大小为 128MiB。在本书中,我们只会用到最低的 8MiB 物理内存,对应的物理地址区间为 [0x80000000,0x80800000) 。
Qemu 模拟的启动流程则可以分为三个阶段:第一个阶段由固化在 Qemu 内的一小段汇编程序负责;第二个阶段由 bootloader 负责;第三个阶段则由内核镜像负责。
- 第一阶段:将必要的文件载入到 Qemu 物理内存之后,Qemu CPU 的程序计数器(PC, Program Counter)会被初始化为
0x1000,因此 Qemu 实际执行的第一条指令位于物理地址0x1000,接下来它将执行寥寥数条指令并跳转到物理地址0x80000000对应的指令处并进入第二阶段。 第二阶段:由于 Qemu 的第一阶段固定跳转到
0x80000000,我们需要将负责第二阶段的 bootloaderrustsbi-qemu.bin放在以物理地址0x80000000开头的物理内存中,这样就能保证0x80000000处正好保存 bootloader 的第一条指令。在这一阶段,bootloader 负责对计算机进行一些初始化工作,并跳转到下一阶段软件的入口,在 Qemu 上即可实现将计算机控制权移交给我们的内核镜像os.bin。- 这里需要注意的是,对于不同的 bootloader 而言,下一阶段软件的入口不一定相同,而且获取这一信息的方式和时间点也不同:入口地址可能是一个预先约定好的固定的值,也有可能是在 bootloader 运行期间才动态获取到的值。我们选用的 RustSBI 则是将下一阶段的入口地址预先约定为固定的
0x80200000,在 RustSBI 的初始化工作完成之后,它会跳转到该地址并将计算机控制权移交给下一阶段的软件——也即我们的内核镜像。
- 这里需要注意的是,对于不同的 bootloader 而言,下一阶段软件的入口不一定相同,而且获取这一信息的方式和时间点也不同:入口地址可能是一个预先约定好的固定的值,也有可能是在 bootloader 运行期间才动态获取到的值。我们选用的 RustSBI 则是将下一阶段的入口地址预先约定为固定的
- 第三阶段:为了正确地和上一阶段的 RustSBI 对接,我们需要保证内核的第一条指令位于物理地址
0x80200000处。为此,我们需要将内核镜像预先加载到 Qemu 物理内存以地址0x80200000开头的区域上。一旦 CPU 开始执行内核的第一条指令,证明计算机的控制权已经被移交给我们的内核,也就达到了本节的目标。
程序内存布局 Memory Layout

在我们将源代码编译为可执行文件之后,它就会变成一个看似充满了杂乱无章的字节的一个文件。但我们知道这些字节至少可以分成代码和数据两部分,在程序运行起来的时候它们的功能并不相同:代码部分由一条条可以被 CPU 解码并执行的指令组成,而数据部分只是被 CPU 视作可读写的内存空间。
已初始化数据段保存程序中那些已初始化的全局数据,分为
.rodata和.data两部分。.rodata存放只读的全局数据,通常是一些常数或者是常量字符串等;.data存放可修改的全局数据。
- 未初始化数据段
.bss保存程序中那些未初始化的全局数据,通常由程序的加载者代为进行零初始化,即将这块区域逐字节清零; - 堆 (heap)区域用来存放程序运行时动态分配的数据,如 C/C++ 中的 malloc/new 分配到的数据本体就放在堆区域,它向高地址增长;
- 栈 (stack)区域不仅用作函数调用上下文的保存与恢复,每个函数作用域内的局部变量也被编译器放在它的栈帧内,它向低地址增长。
编译流程
从源代码得到可执行文件的编译流程可被细化为多个阶段(虽然输入一条命令便可将它们全部完成):
- 编译器 (Compiler) 将每个源文件从某门高级编程语言转化为汇编语言,注意此时源文件仍然是一个 ASCII 或其他编码的文本文件;
- 汇编器 (Assembler) 将上一步的每个源文件中的文本格式的指令转化为机器码,得到一个二进制的 目标文件 (Object File);
- 链接器 (Linker) 将上一步得到的所有目标文件以及一些可能的外部目标文件链接在一起形成一个完整的可执行文件。
汇编器输出的每个目标文件都有一个独立的程序内存布局,它描述了目标文件内各段所在的位置。而链接器所做的事情是将所有输入的目标文件整合成一个整体的内存布局。在此期间链接器主要完成两件事情:
- 第一件事情是将来自不同目标文件的段在目标内存布局中重新排布。如下图所示,在链接过程中,分别来自于目标文件
1.o和2.o段被按照段的功能进行分类,相同功能的段被排在一起放在拼装后的目标文件output.o中。注意到,目标文件1.o和2.o的内存布局是存在冲突的,同一个地址在不同的内存布局中存放不同的内容。而在合并后的内存布局中,这些冲突被消除。

第二件事情是将符号替换为具体地址。这里的符号指什么呢?我们知道,在我们进行模块化编程的时候,每个模块都会提供一些向其他模块公开的全局变量、函数等供其他模块访问,也会访问其他模块向它公开的内容。
要访问一个变量或者调用一个函数,在源代码级别我们只需知道它们的名字即可,这些名字被我们称为符号。 取决于符号来自于模块内部还是其他模块,我们还可以进一步将符号分成内部符号和外部符号。
然而,在机器码级别(也即在目标文件或可执行文件中)我们并不是通过符号来找到索引我们想要访问的变量或函数,而是直接通过变量或函数的地址。例如,如果想调用一个函数,那么在指令的机器码中我们可以找到函数入口的绝对地址或者相对于当前 PC 的相对地址。那么,符号何时被替换为具体地址呢?因为符号对应的变量或函数都是放在某个段里面的固定位置(如全局变量往往放在
.bss或者.data段中,而函数则放在.text段中),所以我们需要等待符号所在的段确定了它们在内存布局中的位置之后才能知道它们确切的地址。当一个模块被转化为目标文件之后,它的内部符号就已经在目标文件中被转化为具体的地址了,因为目标文件给出了模块的内存布局,也就意味着模块内的各个段的位置已经被确定了。然而,此时模块所用到的外部符号的地址无法确定。我们需要将这些外部符号记录下来,放在目标文件一个名为符号表(Symbol table)的区域内。由于后续可能还需要重定位,内部符号也同样需要被记录在符号表中。外部符号需要等到链接的时候才能被转化为具体地址。假设模块 1 用到了模块 2 提供的内容,当两个模块的目标文件链接到一起的时候,它们的内存布局会被合并,也就意味着两个模块的各个段的位置均被确定下来。此时,模块 1 用到的来自模块 2 的外部符号可以被转化为具体地址。同时我们还需要注意:两个模块的段在合并后的内存布局中被重新排布,其最终的位置有可能和它们在模块自身的局部内存布局中的位置相比已经发生了变化。因此,每个模块的内部符号的地址也有可能会发生变化,我们也需要进行修正。上面的过程被称为重定位(Relocation),这个过程形象一些来说很像拼图:由于模块 1 用到了模块 2 的内容,因此二者分别相当于一块凹进和凸出一部分的拼图,正因如此我们可以将它们无缝地拼接到一起。
在 Qemu 上执行内核的第一条指令
我们先编写好内核第一条指令并嵌入到内核项目中。
编写第一条指令
# os/src/entry.asm
.section .text.entry
.globl _start
_start:
li x1, 100- 第 2 行表明我们希望将第 2 行后面的内容全部放到一个名为
.text.entry的段中。一般情况下,所有的代码都被放到一个名为.text的代码段中,这里我们将其命名为.text.entry从而区别于其他.text的目的在于我们想要确保该段被放置在相比任何其他代码段更低的地址上。这样,作为内核的入口点,这段指令才能被最先执行。 - 第 3 行我们告知编译器
_start是一个全局符号,因此可以被其他目标文件使用。 - 符号
_start的地址即为第 5 行的指令所在的地址。
调整内核布局与 Qemu 正确对接
内核第一条指令(实践篇) - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档
由于链接器默认的内存布局并不能符合我们的要求,为了实现与 Qemu 正确对接,我们可以通过 链接脚本 (Linker Script) 调整链接器的行为,使得最终生成的可执行文件的内存布局符合 Qemu 的预期,即内核第一条指令的地址应该位于 0x80200000 。我们修改 Cargo 的配置文件来使用我们自己的链接脚本 os/src/linker.ld 而非使用默认的内存布局。
手动加载内核可执行文件
上面通过链接得到的文件完全符合我们对于内存布局的要求,但是我们不能将其直接提交给 Qemu ,因为它除了实际会被用到的代码和数据段之外还有一些多余的元数据,这些元数据无法被 Qemu 在加载文件时利用,且会使代码和数据段被加载到错误的位置。
我们需要丢弃内核可执行文件中的元数据得到内核镜像。
rust-objcopy --strip-all target/riscv64gc-unknown-none-elf/release/os -O binary target/riscv64gc-unknown-none-elf/release/os.bin为内核提供函数调用——将控制权交给Rust
上一节我们成功在 Qemu 上执行了内核的第一条指令,它是我们在 entry.asm 中手写汇编代码得到的。然而,我们无论如何也不想仅靠手写汇编代码的方式编写我们的内核,绝大部分功能我们都想使用 Rust 语言来实现。
不过为了将控制权转交给我们使用 Rust 语言编写的内核入口函数,我们确实需要手写若干行汇编代码进行一定的初始化工作。这些汇编代码放在 entry.asm 中,并在控制权被转交给内核相关函数前最先被执行,但它们的功能会更加复杂。首先需要设置栈空间,来在内核内使能函数调用,随后直接调用使用 Rust 编写的内核入口函数,从而控制权便被移交给 Rust 代码。
函数调用与栈
从汇编指令的级别看待一段程序的执行,假如 CPU 依次执行的指令的物理地址序列为 {an},那么这个序列会符合怎样的模式呢?
- CPU 一条条连续向下执行指令,即满足递推公式 an+1 = an + L,这里我们假设该平台的指令是定长的且均为 L 字节(常见情况为 2/4 字节)。
- 当位于物理地址 an 的指令是一条跳转指令的时候,该模式就有可能被破坏。跳转指令对应于我们在程序中构造的 控制流 (Control Flow) 的多种不同结构,比如分支结构(如 if/switch 语句)和循环结构(如 for/while 语句)。用来实现上述两种结构的跳转指令,只需实现跳转功能,也就是将 pc 寄存器设置到一个指定的地址即可。
- 另一种控制流结构:函数调用 (Function Call)。调用的时候,需要有一条指令跳转到被调用函数的位置。函数调用的返回跳转是跳转到一个 _运行时确定_ (确切地说是在函数调用发生的时候)的地址。

编译器是独立编译每个函数的,因此一个函数并不能知道它所调用的子函数修改了哪些寄存器。而站在一个函数的视角,在调用子函数的过程中某些寄存器的值被覆盖的确会对它接下来的执行产生影响。
我们将由于函数调用,在控制流转移前后需要保持不变的寄存器集合称之为 函数调用上下文 (Function Call Context) 。
由于每个 CPU 只有一套寄存器,我们若想在子函数调用前后保持函数调用上下文不变,就需要物理内存的帮助。在调用子函数之前,我们需要在物理内存中的一个区域栈Stack 保存 (Save) 函数调用上下文中的寄存器;而在函数执行完毕后,我们会从内存中同样的区域读取并 恢复 (Restore) 函数调用上下文中的寄存器。实际上,这一工作是由子函数的调用者和被调用者(也就是子函数自身)合作完成。函数调用上下文中的寄存器被分为如下两类:
- 被调用者保存(Callee-Saved) 寄存器 :被调用的函数可能会覆盖这些寄存器,需要被调用的函数来保存的寄存器,即由被调用的函数来保证在调用前后,这些寄存器保持不变;
- 调用者保存(Caller-Saved) 寄存器 :被调用的函数可能会覆盖这些寄存器,需要发起调用的函数来保存的寄存器,即由发起调用的函数来保证在调用前后,这些寄存器保持不变。
RISC-V 架构上的 C 语言调用规范
|寄存器组|保存者|功能|
|---|---|---|
|a0~a7( x10~x17 )|调用者保存|用来传递输入参数。其中的 a0 和 a1 还用来保存返回值。|
|t0~t6 ( x5~x7,x28~x31 )|调用者保存|作为临时寄存器使用,在被调函数中可以随意使用无需保存。|
|s0~s11 ( x8~x9,x18~x27 )|被调用者保存|作为临时寄存器使用,被调函数保存后才能在被调函数中使用。|
分配并使用启动栈
# os/src/entry.asm
.section .text.entry
.globl _start
_start:
la sp, boot_stack_top
call rust_main
.section .bss.stack
.globl boot_stack_lower_bound
boot_stack_lower_bound:
.space 4096 * 16
.globl boot_stack_top
boot_stack_top:栈是从高地址向低地址增长。因此,最开始的时候栈为空,栈顶和栈底位于相同的位置,我们用更高地址的符号 boot_stack_top 来标识栈顶的位置。同时,我们用更低地址的符号 boot_stack_lower_bound 来标识栈能够增长到的下限位置,它们都被设置为全局符号供其他目标文件使用。如下图所示:

内核调用 RustSBI 服务
之前我们对 RustSBI 的了解仅限于它会在计算机启动时进行它所负责的环境初始化工作,并将计算机控制权移交给内核。但实际上作为内核的执行环境,它还有另一项职责:即在内核运行时响应内核的请求为内核提供服务。当内核发出请求时,计算机会转由 RustSBI 控制来响应内核的请求,待请求处理完毕后,计算机控制权会被交还给内核。